
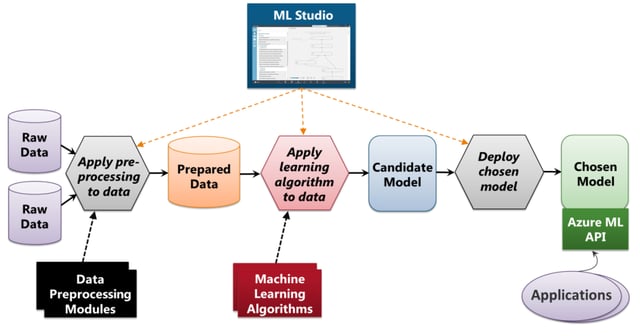
The first step is to obtain raw data for past property sales via the land registry or real estate company. If possible, every transaction over the last eighteen months. The raw data should include all the input fields, plus many others - and of course the actual sale price. Each field in AML is known as a feature.
Let’s imagine we have the following very simplified raw data in CSV file format:
bedrooms, bathrooms, mainrooms, value
3,1,2,200000
3,1,2,200000
5,2,3,500000
4,2,0,450000
The next step is to create prepared data, by pre-processing the raw data. The pre-processing entails machine learning modules to de-duplicate rows, delete rows with missing data and delete rows with invalid data. Hence for the above data we would discard rows 1 and 4.
Module processing can also include changing the type of the data, e.g from a string value to numeric value. Any column features that do not affect the worth of the property should also be removed, and any necessary maths operations could be applied to the data.
The prepared data is then split 80:20, keeping the latter back as test input and the former now known as training data.
Next is to create an experiment. The data scientist chooses a single algorithm from a set of pre-prepared machine learning algorithms. In this scenario, the scientist is looking for an algorithm, that when executed, can analyse the training data, and return the best numerical combination of features that gives the closest predicted values (also known as target values or labels) against each actual value. Below is an extremely simplified algorithm that can demonstrate this:
predicted value = (a* bedrooms) + (b* bathrooms) + (c* mainrooms)
Hence the algorithm uses the features of the training data (bedroom, bathroom, mainrooms etc) to determine the best values of a, b and c, the weightings. If each feature was found to have an equal weighting of 30,000, then for row 1 the predicted value would be: £180,000 compare to actual value of £200,000.
predicted value = (30000* 3) + (30000* 1) + (30000* 2)
When a machine learning algorithm execution completes, the candidate combination is internally saved as code and is known as the model. This process is usually repeated numerous times until the best model is found. This is known as training the model. For each saved model, we can use the test data to evaluate the statistical accuracy of the model. Hence our candidate model would be:
predicted value = 30000 (bedrooms + bathrooms + mainrooms)
In our house example, we could have started with any of the regression machine learning algorithms. This could give us satisfactory results as property prices might be linearly proportional to the values of property features.
Finally, when we have produced our best model we can deploy it to Azure as a web API. The app then prompts for the input features, submits them to the API, the model returns a predicted property value and the app displays this value.
The whole AML cycle can be demonstrated in the diagram below:
Further Reading:
For this particular problem, we have been looking to produce a linear, or scalar value, such as money - and so we could choose algorithms that fit this. These include: Bayesian Linear Regression, Boosted Decision Tree Regression and Neural Network Regression. The choice of algorithm is crucial to gaining a satisfactory result.
A different problem might be to produce two or more categories of result. An email spam filtering model will input an email and return one of two values: spam or not spam. Or, a model that determines a dog breed will return many different results. Both of these problems require category based algorithms such as: Multiclass Decision Jungle, Two-Class Boosted Decision Tree or One-vs-All Multiclass.
Another problem might be that we have many bitmap images of petri dishes containing cultures that have been impregnated with potential new antibiotics. We will want to place each dish into clusters of; not effective, slightly effective and very effective using the K-Means Clustering algorithm.
If you have any queries about AML, or would like to discuss this in further detail please don't hesitate to contact us.

- By Nigel Wardle (Application Architect)

