
For years, as developers we have chosen by default some form of SQL or relational database management system (RDBMS) to store application data. But now we are entering the age of the cloud, alternatives are beginning to appear. So how does RDBMS fair?
Reasonably well... If we consider SQL Azure - which is a cloud version of Microsoft SQL Server - it supports encryption both in transit and at rest. It automates much that a database administrator (DBA) would, such as – table indexing, backup and replication to other instances. We still have to distribute (or normalise) our data across related tables – so nothing has changed there. If we are using C#, then we can configure our code to automatically generate the database table structure (schema) using Entity Framework in ‘code first’ mode.
What’s wrong with RDBMS?It can’t ‘scale out’ or ‘horizontally scale’ for truly global data storage – meaning we can’t simply add a new second server when more writable resources are required. It can only ‘scale up’ by configuring the cloud service to provide more resources – allocating more processing power or memory to the server. The bottom line is; there is only one writable database on one server, on one virtual machine - and a number of read only copies.
CosmosDB
So what is CosmosDB, what is different about it, and and under what circumstances can we consider it? CosmosDB is Microsoft’s new cloud native database which comes in different forms. In this article we discuss its document database (DocumentDB) form.
CosmosDB Document Store hosts data records in collections of JavaScript Object Notation (JSON) text files. Instead of distributing the data across many relational tables, the complete record can be kept together in a single document. When we query or read the record, it simply returns the data from the single document. Compare this to RDBMS which first has to work out how to join the data from separate tables in an efficient manner before it can do anything. Hence reading data from DocumentDB can have extremely low latency, allowing for results at lightning speeds.
Another advantage is that these documents can be copied or replicated to many CosmosDB instances. Each copy can be further edited and replicated back, as such no particular document is the master. All databases are writable and we can have as many database instances as we like - allowing us to ‘scale up’ and ‘scale out’. Additionally, we can inform CosmosDB how to partition the data. This means that we can specify a field in our document as a partition and it can place documents with the same partition on the same server, and other partition values onto other servers. CosmosDB also has five levels of consistency compared to the one in most RDBMS – but we won't go into this today!
So we can execute queries that save documents, return one or more documents, or even return portions (projections) of documents. But what if the information is scattered across many documents? In this scenario, the client app has the extra work of making sense of the results and pickimg out what is needed. Why not duplicate and maintain this data in another single document instead?
Optimised JSON Documents
We have been so used to normalising our data into separate tables that the idea of doing this can make us uncomfortable. To do this we need to rethink how we store our JSON documents so they are optimised for the read and write tasks we want our application to perform. In our SQL past we would have normalised to the nth degree, without caring too much about the way our applications might read or write data. Of course, we would make certain that we created sufficient table indexes to avoid full table scans!
Let’s look at an example of how we can typically store data relating to a person's contact details in a 4 table relational database. We can obtain a person record by executing a single query of the database, but incurring an expensive join between the 4 tables:

If we then wanted to update a field in each table we would have to submit an individual query update for each table, resulting in five server round trips :
:
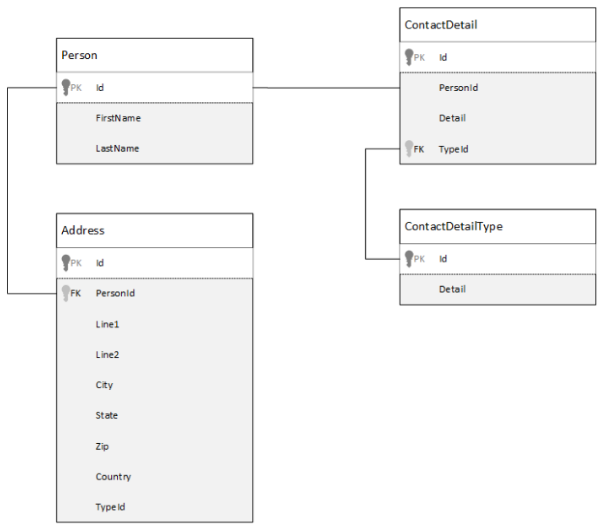
How does CosmosDB compare?
Here we embed the complete record in one document which we can obtain from a single query. We can then update anything in the record and save it back in a single operation. Job done!

The big assumption is that the person has a limited or bounded number of addresses or contact details. If however, we needed to additionally store the date and time for each login, then the corresponding embedded list would grow over time without bounds, possibly growing into megabytes in size. Every time we wanted to edit a single field we would have to download this large document, find the field, then post it back. Hence for performance and code complexity reasons, it would be wise to move login details out of this document and into one or more other documents that can be referenced.
Let’s look at an example of how we could store a many to many unbounded relationship in SQL and also in CosmosDB:

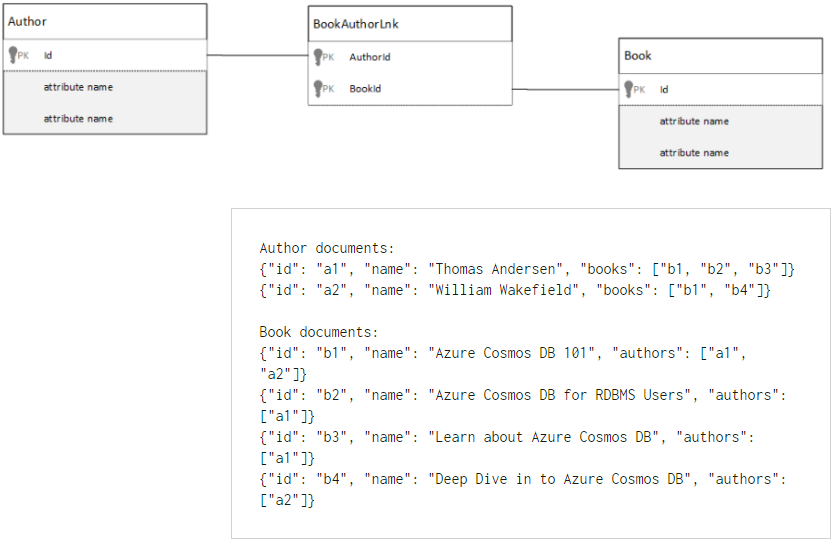
Here we have six individual documents that have embedded items that reference each other by using an id field. This can work well for a small number of items, but might not be optimal if the unbounded number of books or authors increased indefinitely.
Note: References between documents are not checked or enforced. Compare that to enforced Primary Key – Foreign Key relationships in relational databases that maintain database integrity.
In summary, if we only have bounded relationships, then for many reasons CosmosDB can challenge RDBMS. For unbounded relationships, this can take a bit more thought but can work extremely well.
If you have any queries about Azure, or would like to discuss this in further detail please don't hesitate to contact us.

- By Nigel Wardle (Application Architect)

* All links and URLs provided are at the discretion of the author
